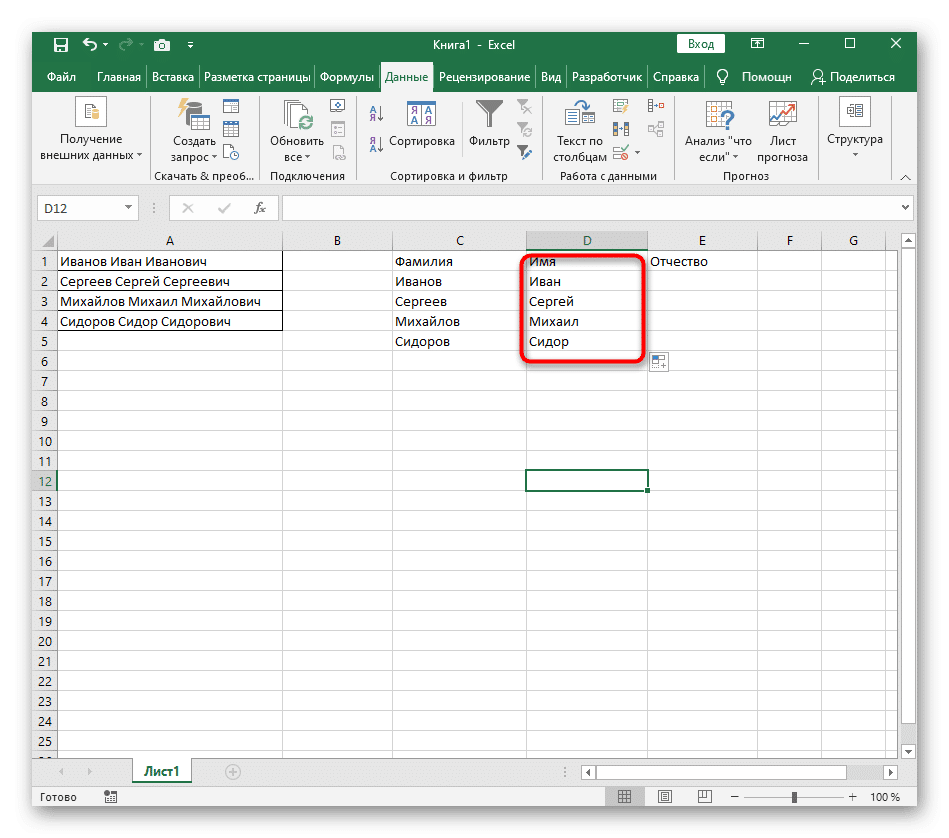
Способ 1: Использование автоматического инструмента
В Excel есть автоматический инструмент для разделения текста на столбцы. В автоматическом режиме он не работает, поэтому все действия придется выполнять вручную, предварительно выбрав диапазон обрабатываемых данных. Однако установка максимально простая и быстрая.
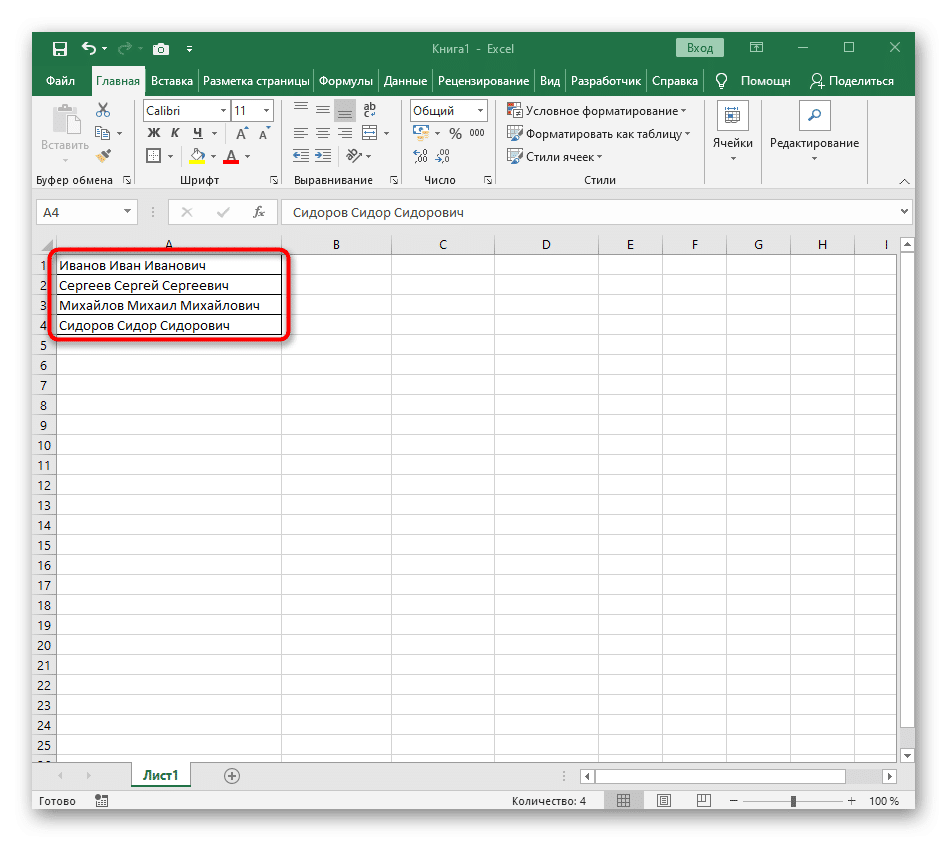
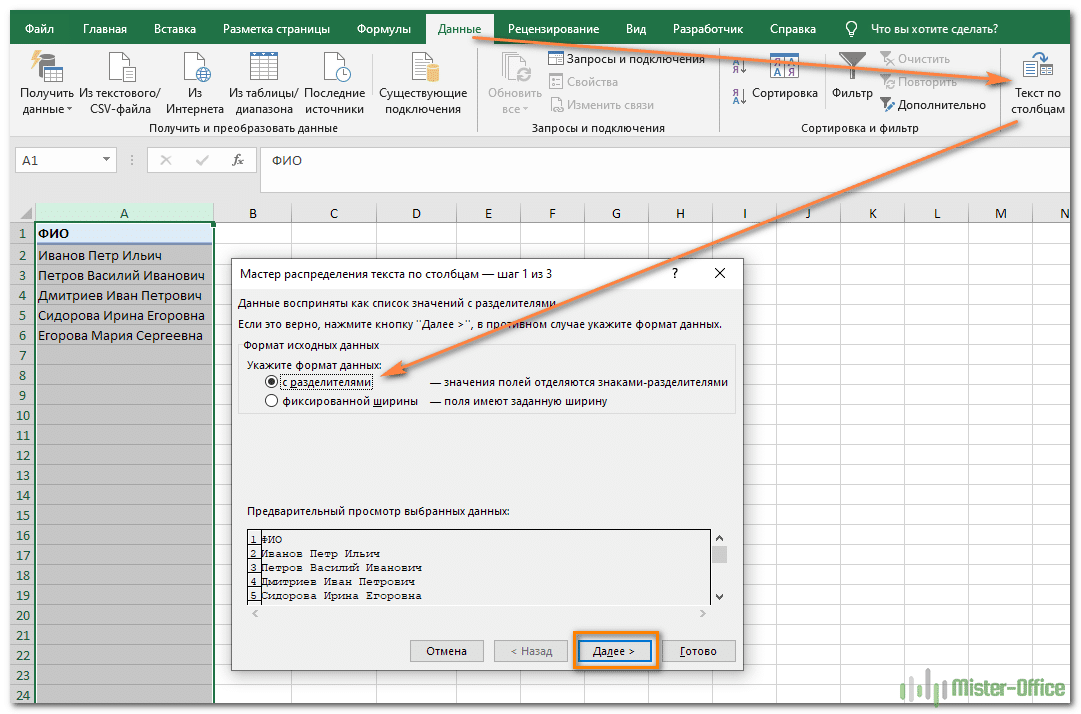
- Удерживая нажатой левую кнопку мыши, выберите все ячейки, текст которых вы хотите разделить на столбцы.
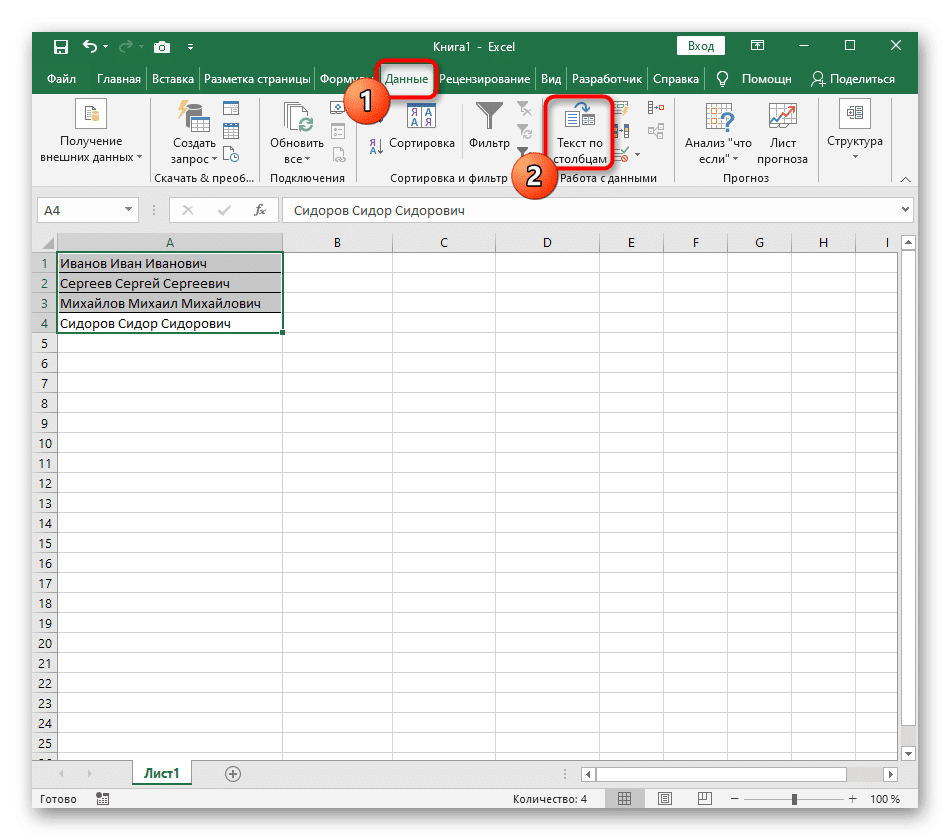
- Затем перейдите на вкладку «Данные» и нажмите кнопку «Текст по столбцам».
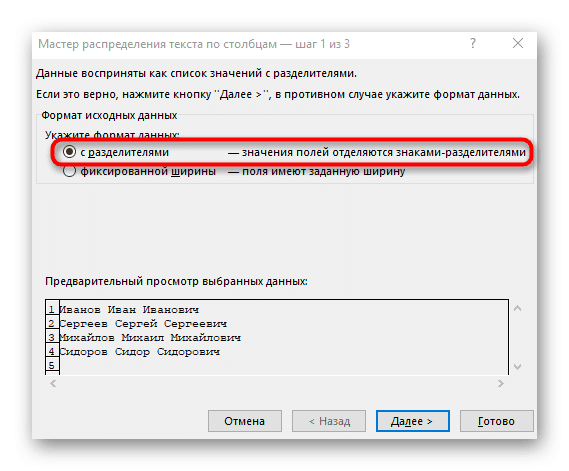
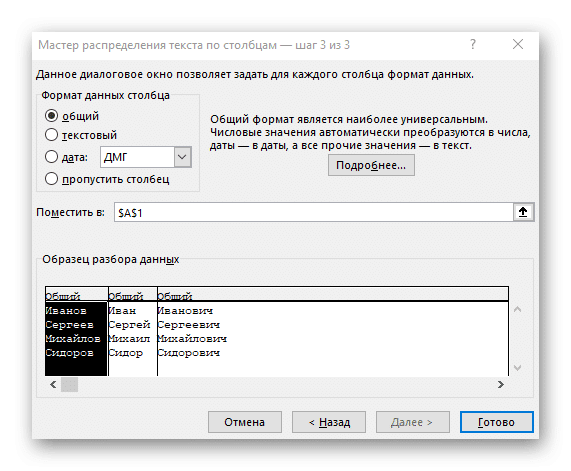
- Появится окно «Мастер разделения текста по столбцам», в котором нужно выбрать формат данных «с разделителями». Разделителем чаще всего является пробел, но если это еще один знак препинания, вам нужно будет указать его на следующем шаге.
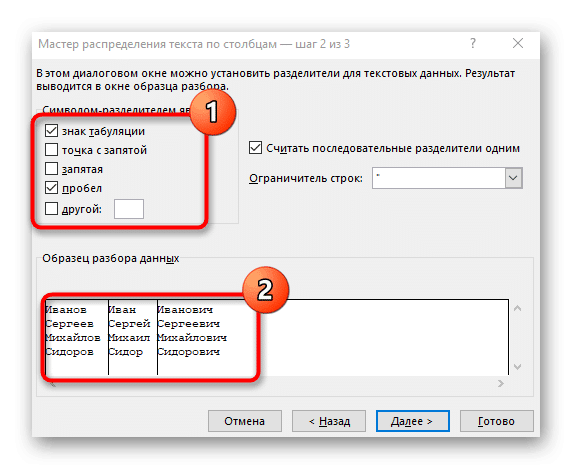
- Установите флажок у символа деления или введите его вручную, после чего посмотрите результат предварительного деления в окне ниже.
- На последнем этапе вы можете указать новый формат столбцов и место их размещения. После завершения настройки нажмите «Готово», чтобы применить все изменения.
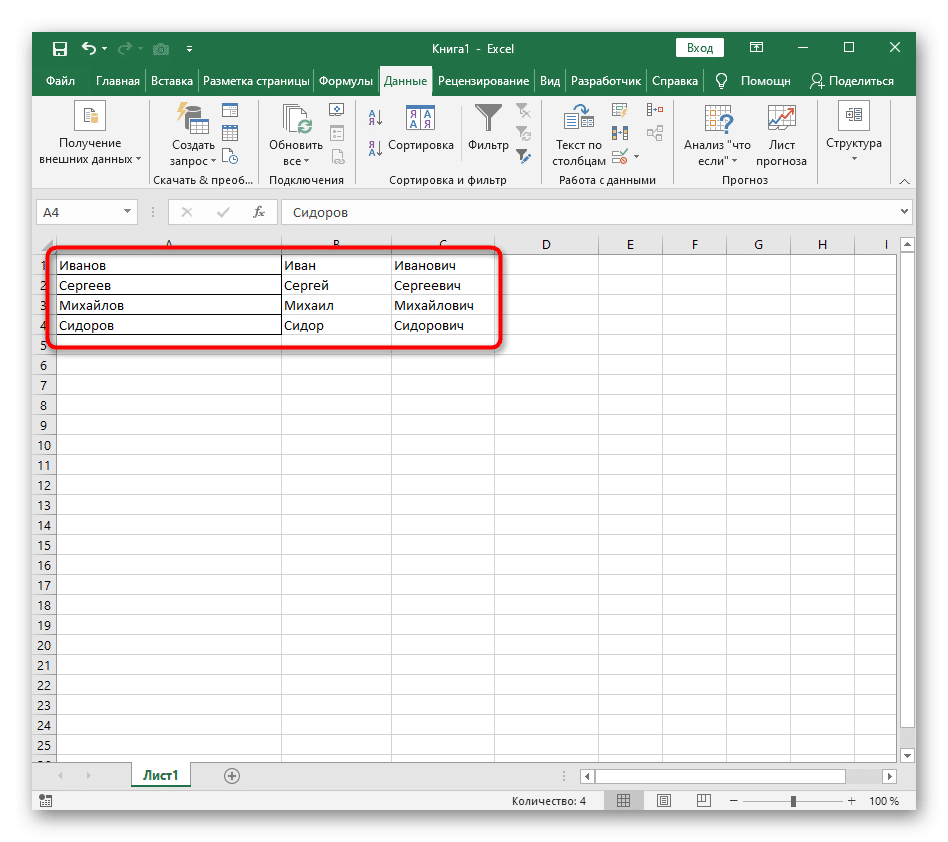
- Вернитесь к столу и убедитесь, что разделение прошло успешно.
Из этого утверждения можно сделать вывод, что использование такого инструмента оптимально в тех ситуациях, когда деление необходимо производить только один раз, обозначая новый столбец для каждого слова. Однако, если в таблицу постоянно вводятся новые данные, будет не совсем удобно разделять их таким образом все время, поэтому в таких случаях мы предлагаем вам ознакомиться со следующим методом.
Способ 2: Создание формулы разделения текста
В Excel вы можете независимо создать относительно сложную формулу, которая будет вычислять позиции слов в ячейке, находить пробелы и разделять их на отдельные столбцы. Например, мы возьмем ячейку с тремя словами, разделенными пробелами. Каждому из них потребуется своя формула, поэтому давайте разделим метод на три этапа.
Шаг 1: Разделение первого слова
Формула для первого слова является самой простой, так как вам нужно только начать с пробела, чтобы определить правильную позицию. Давайте рассмотрим каждый этап его создания, чтобы иметь полное представление о том, зачем нужны те или иные вычисления.
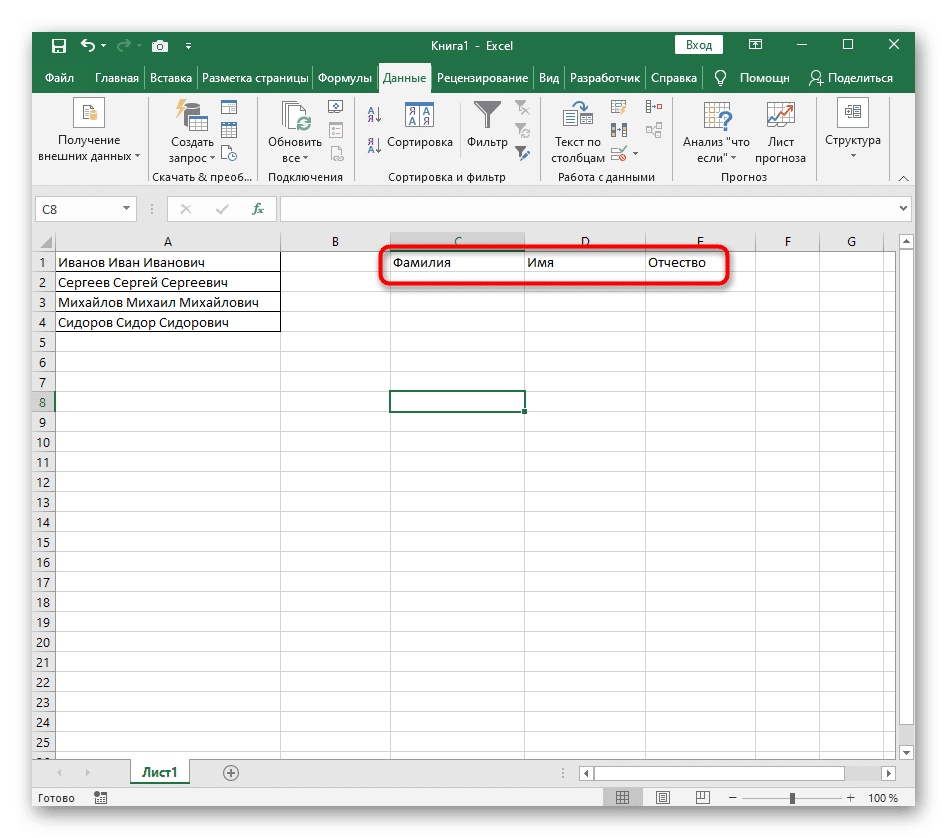
- Для вашего удобства мы создадим три новых столбца с заголовками, в которые добавим разделенный текст. Вы можете сделать то же самое, а можете пропустить этот момент.
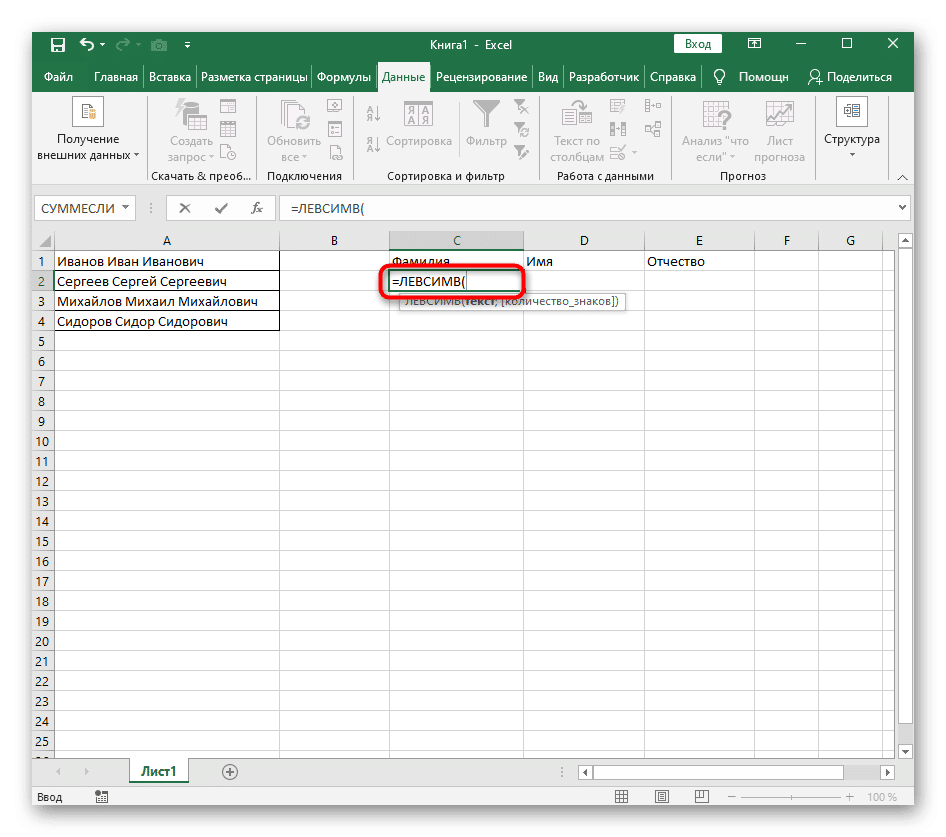
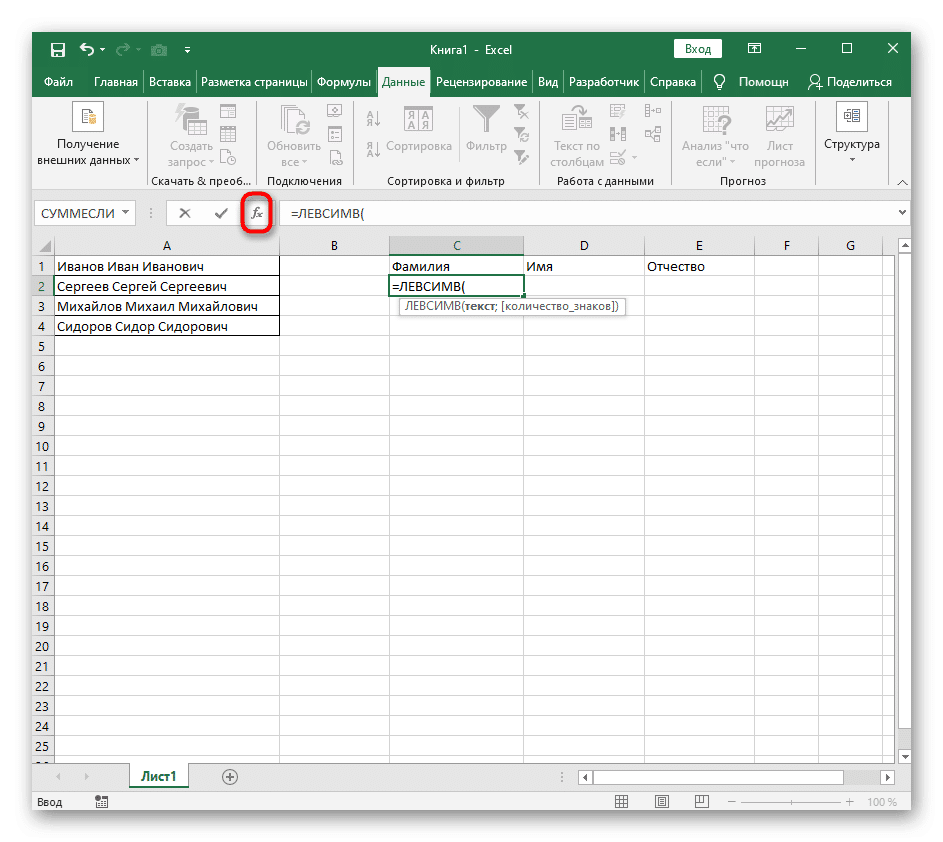
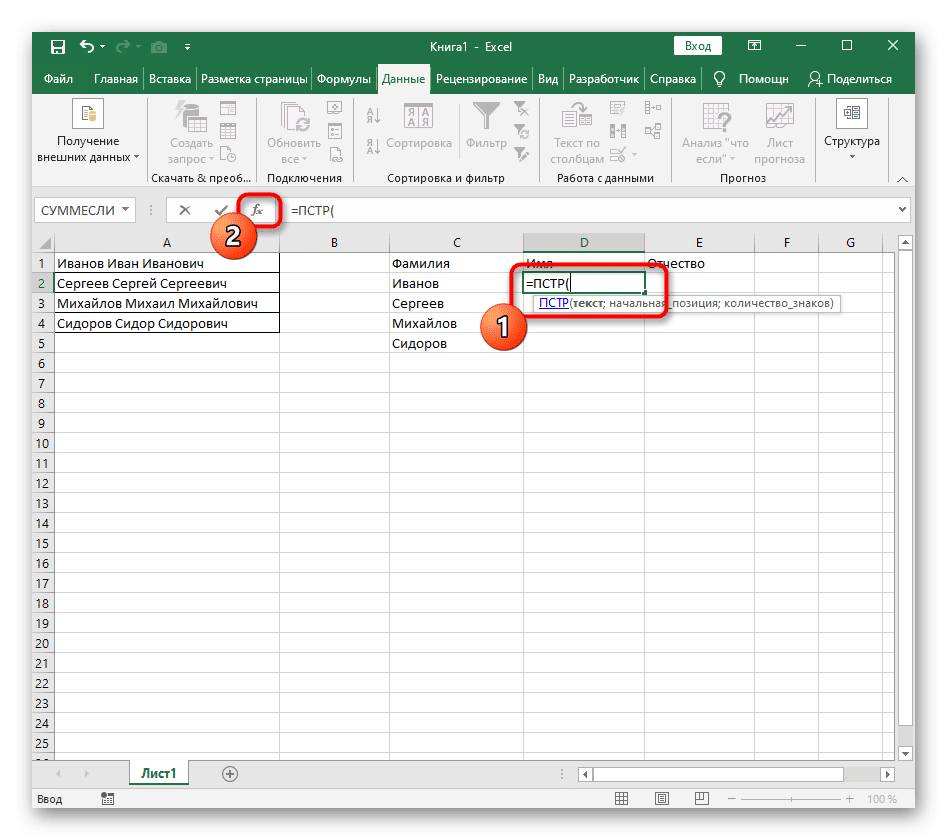
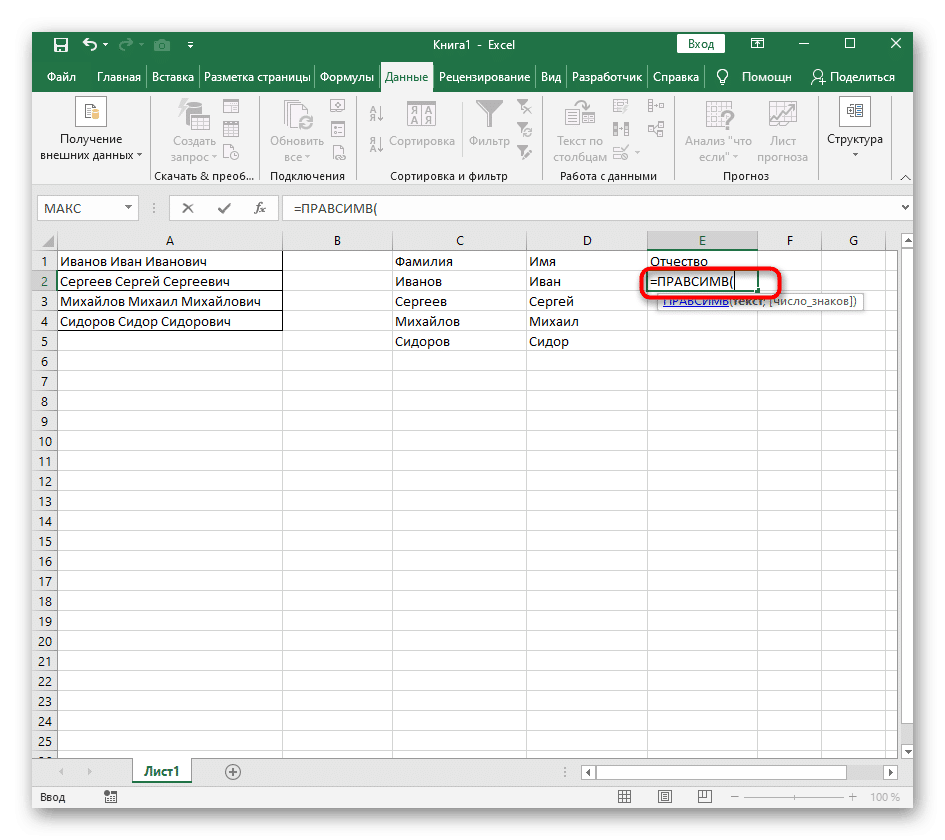
- Выберите ячейку, в которую вы хотите вставить первое слово, и напишите формулу = ЛЕВЫЙ(.
- Затем нажмите кнопку «Аргументы функции», чтобы перейти в графическое окно для редактирования формулы.
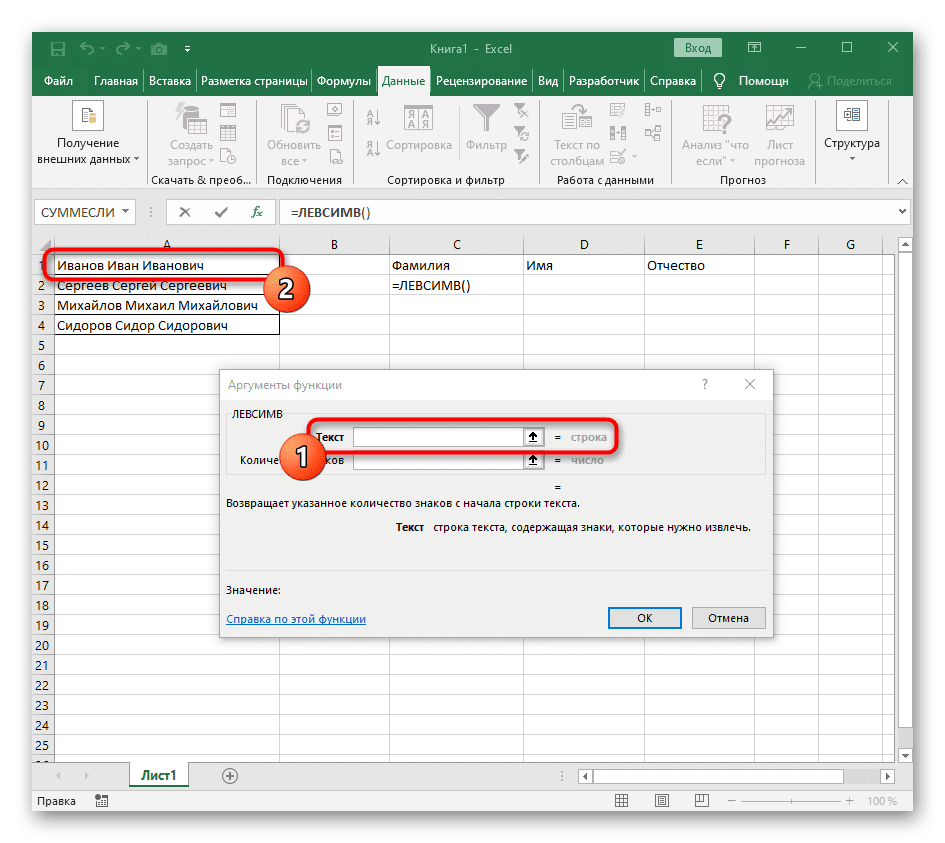
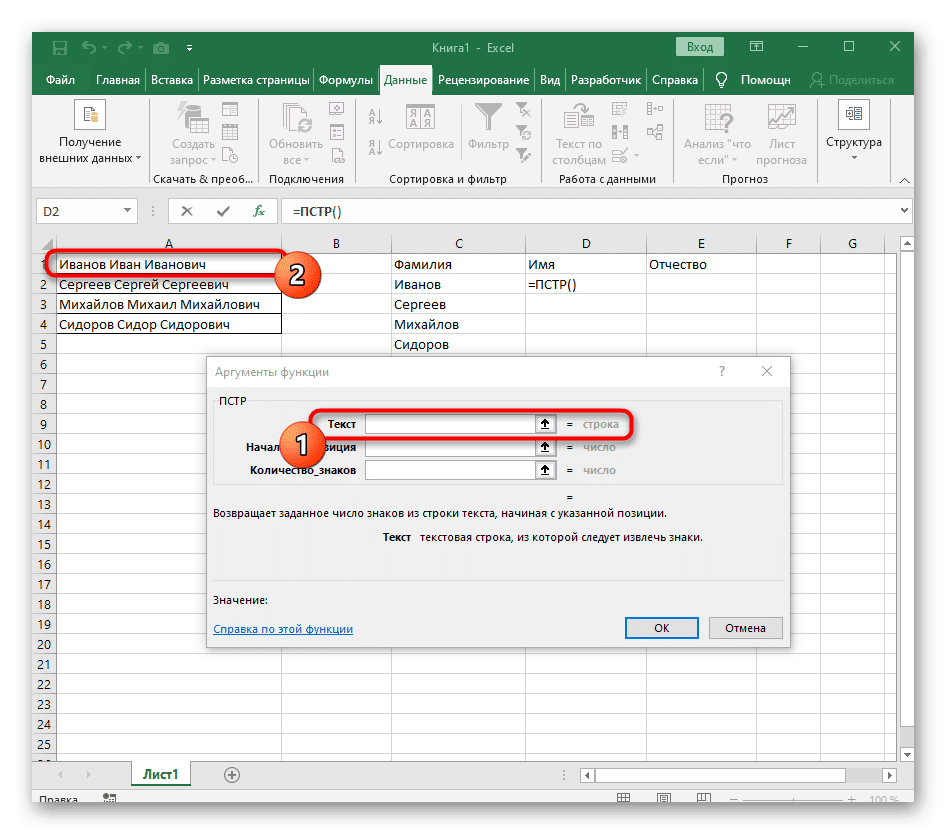
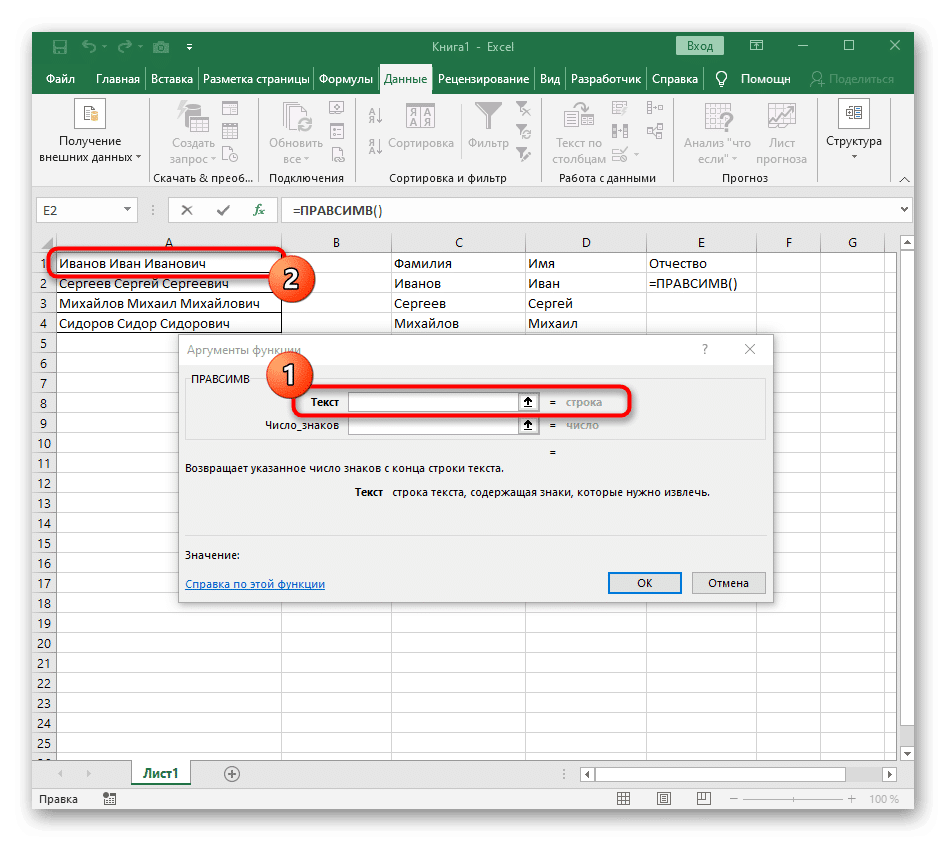
- Укажите ячейку с подписью как текст темы, щелкнув по ней левой кнопкой мыши на таблице.
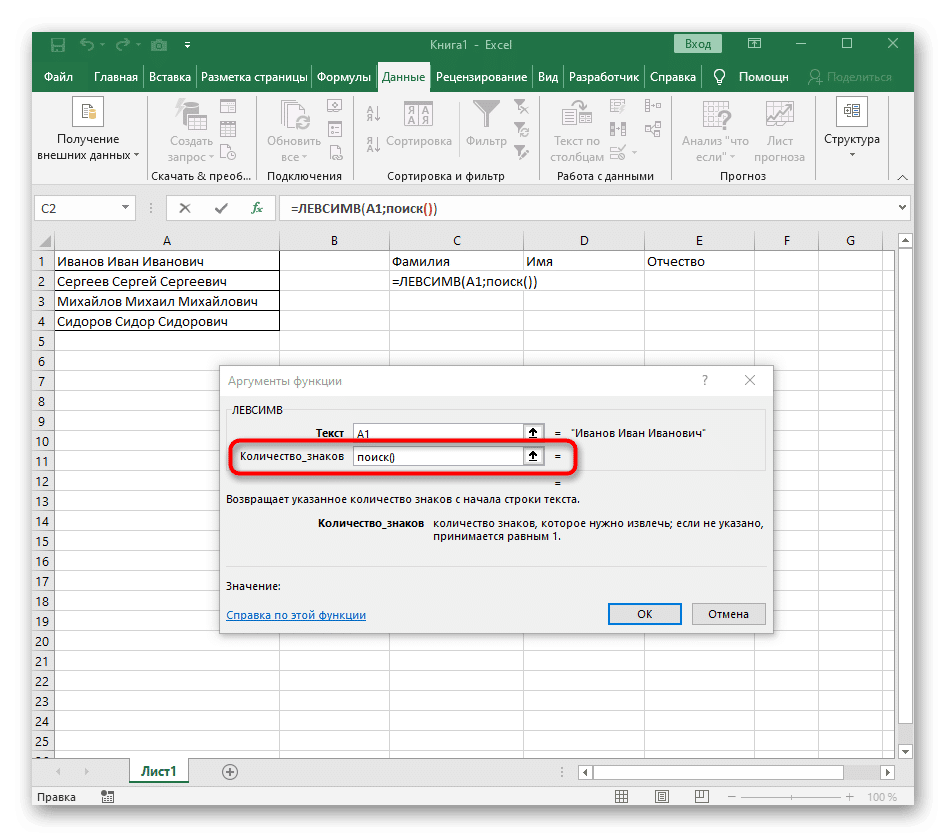
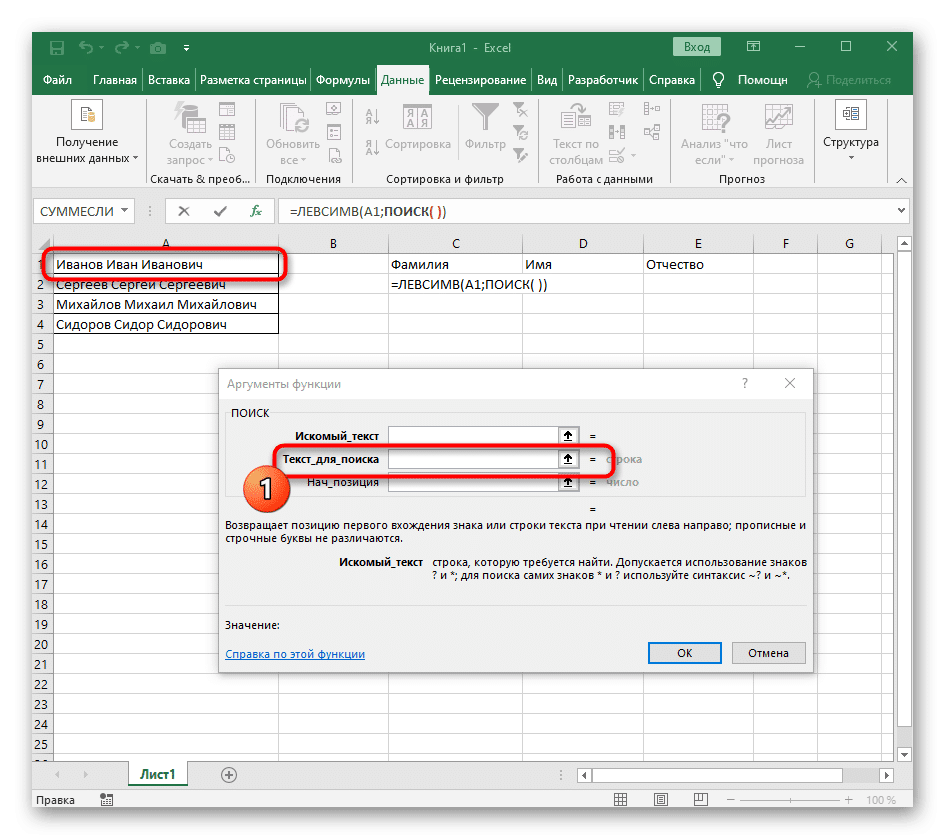
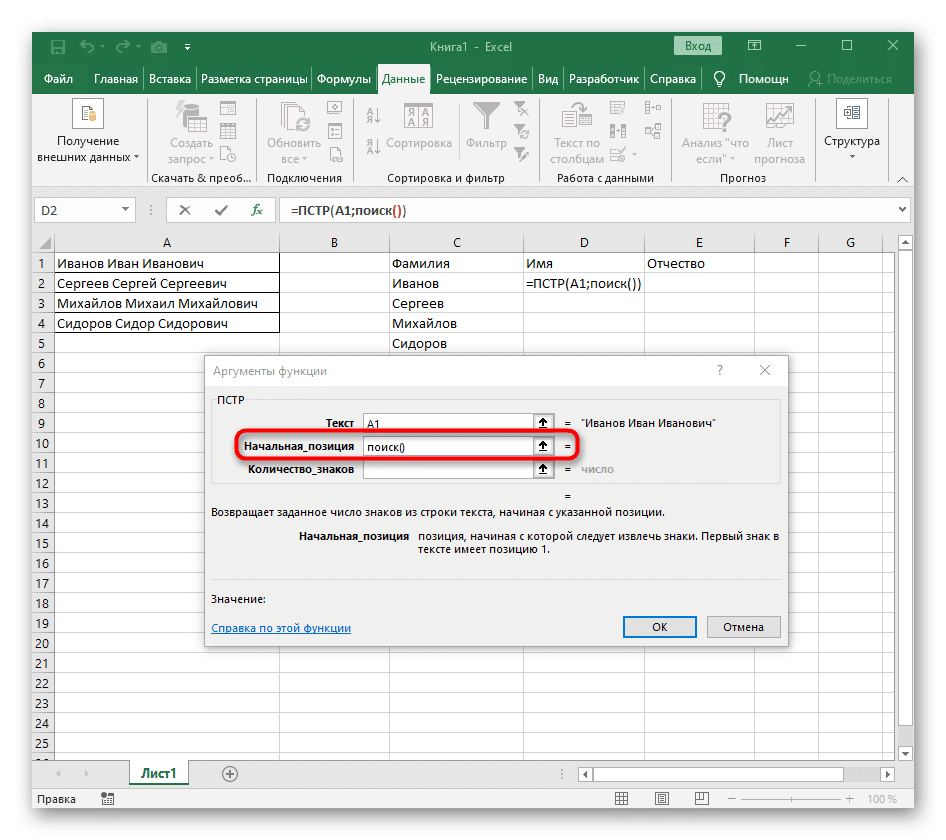
- Количество символов перед пробелом или другим разделителем нужно будет посчитать, но мы не будем делать это вручную, а воспользуемся другой формулой — ПОИСК().
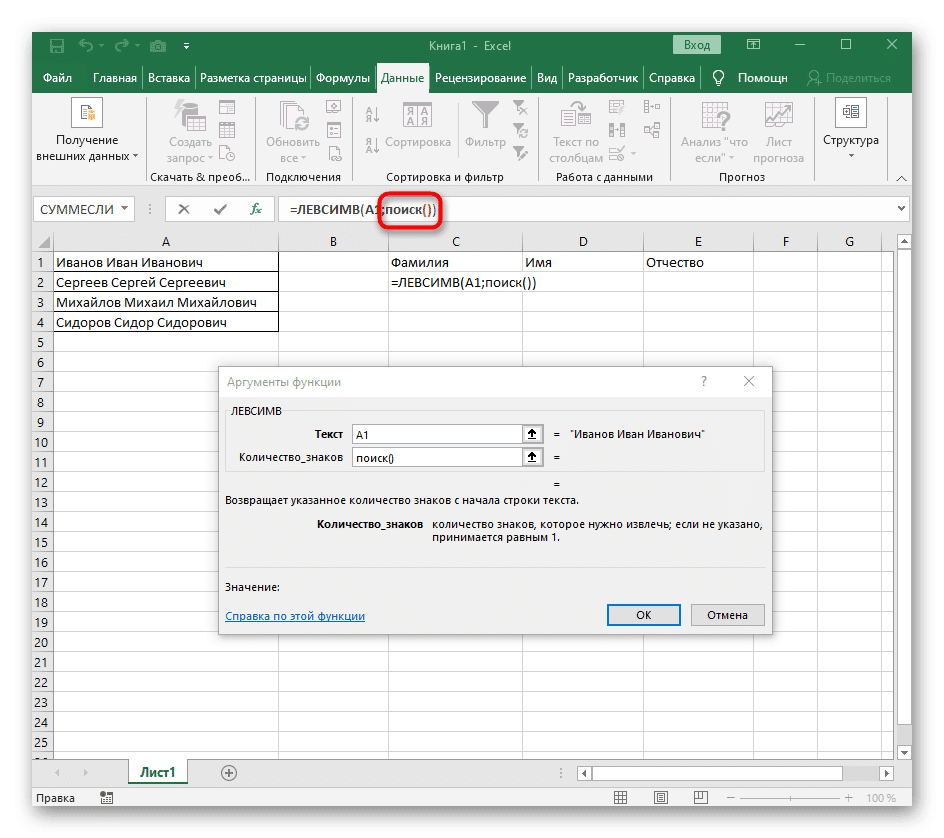
- Как только вы введете его в этом формате, он появится в тексте верхней ячейки и будет выделен жирным шрифтом. Щелкните по нему, чтобы быстро перейти к аргументам этой функции.
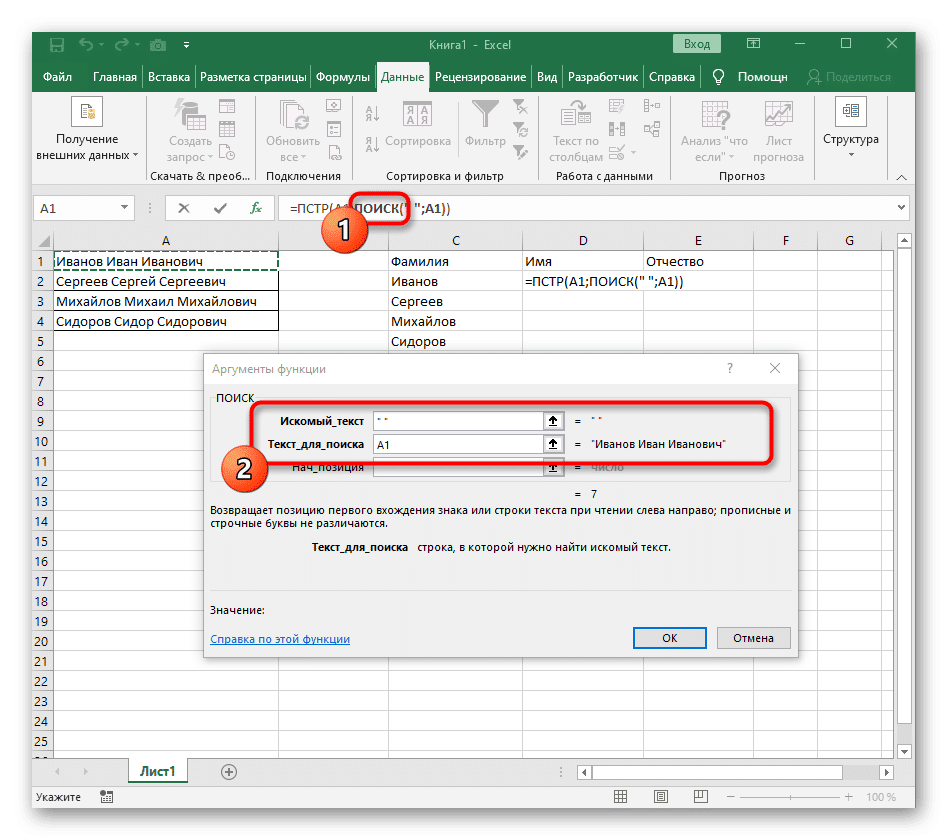
- В поле «Lookup_text» просто введите пробел или разделитель, который вы используете, так как это поможет вам понять, где заканчивается слово. В «Text_For_Search» укажите ту же обрабатываемую ячейку.
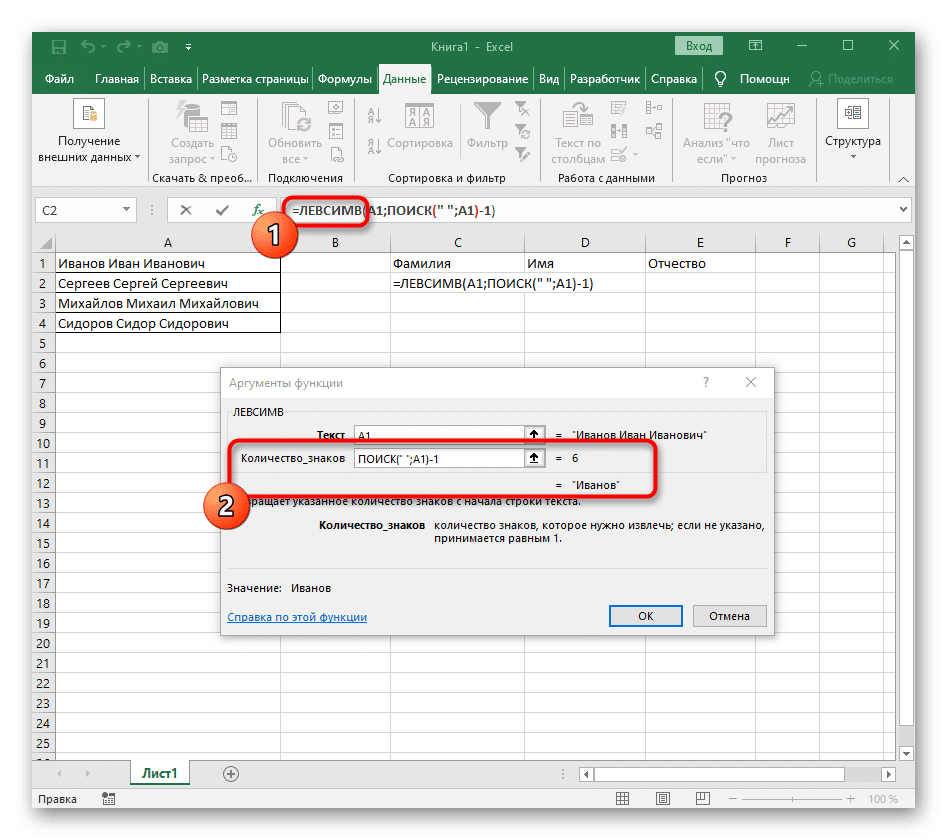
- Щелкните первую функцию, чтобы вернуться к ней, и добавьте -1 в конец второго аргумента. Это необходимо для того, чтобы формула «ПОИСК» учитывала не требуемый пробел, а предшествующий ему символ. Как вы можете видеть на скриншоте ниже, результатом является фамилия без пробелов, что означает, что формулы написаны правильно.
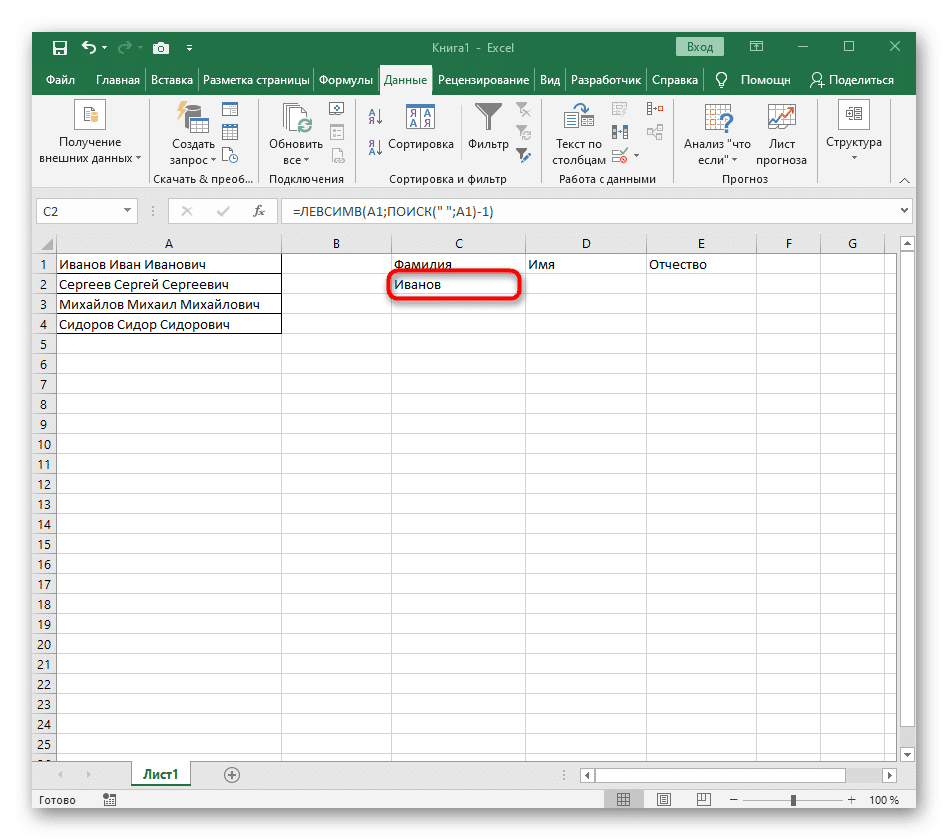
- Закройте редактор функций и убедитесь, что слово правильно отображается в новой ячейке.
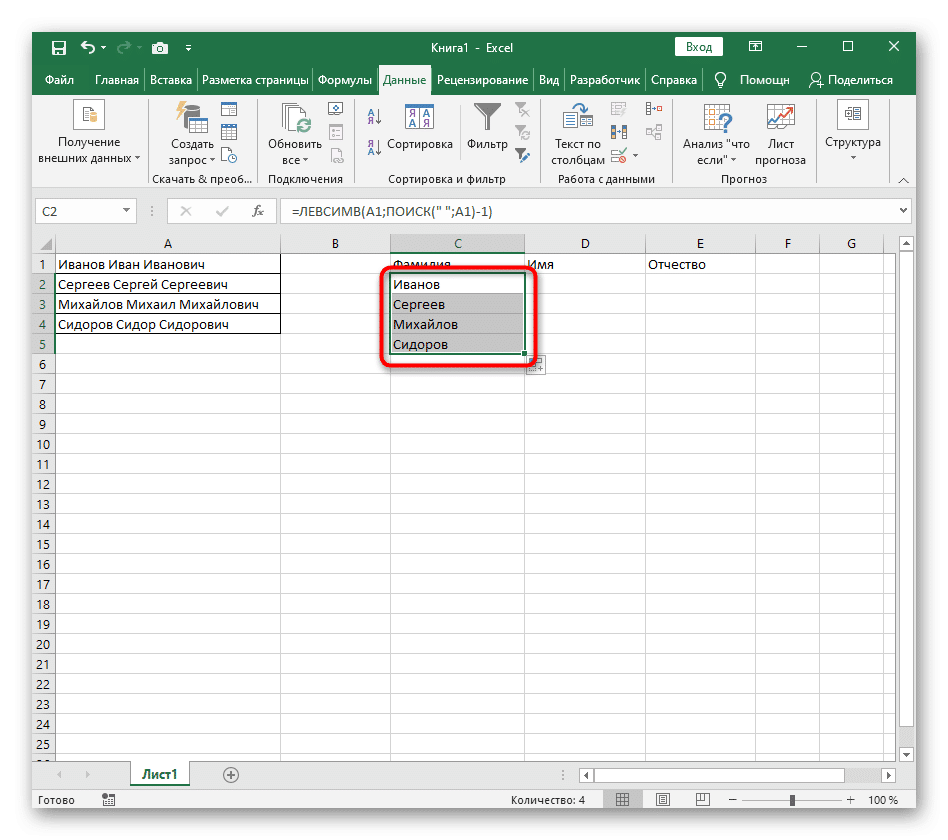
- Сожмите ячейку в правом нижнем углу и потяните вниз столько линий, сколько нужно, чтобы растянуть ее. Это заменяет значения других выражений, которые необходимо разделить, и формула запускается автоматически.
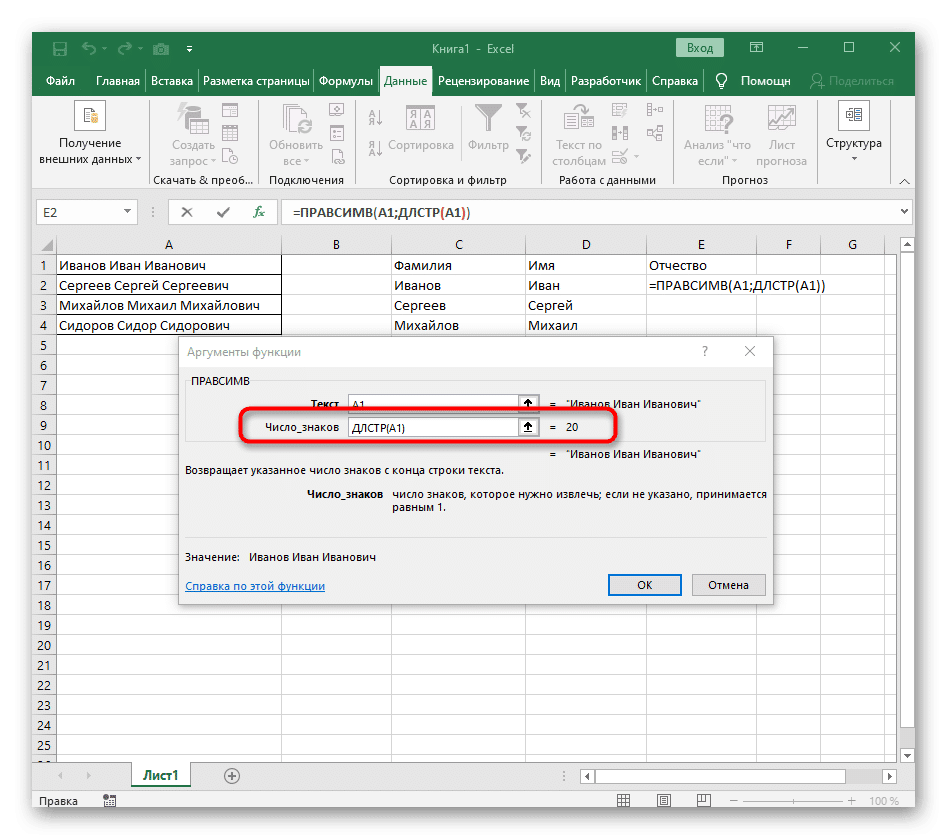
Полностью созданная формула выглядит как = ЛЕВЫЙ (A1; ПОИСК («»; A1) -1), вы можете создать ее в соответствии с приведенными выше инструкциями или ввести, если подходят условия и разделитель. Не забудьте заменить обрабатываемую ячейку.
Шаг 2: Разделение второго слова
Самое сложное — отделить второе слово, которым в нашем случае является имя. Это связано с тем, что он окружен пробелами с обеих сторон, поэтому вам придется учитывать их оба, создавая массивную формулу для правильного расчета позиции.
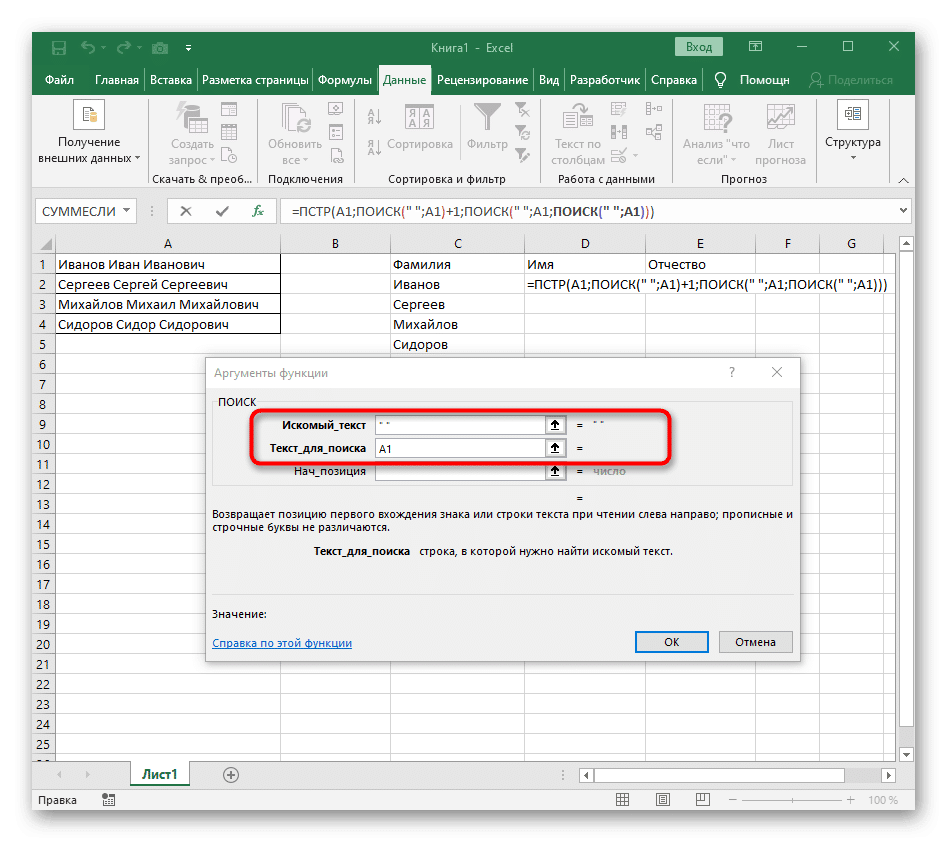
- В этом случае основная формула станет = MID (- запишите ее в этой форме, затем перейдите в окно настройки аргументов.
- Эта формула будет искать нужную строку в тексте, поскольку мы выделяем ячейку с заголовком для разделения.
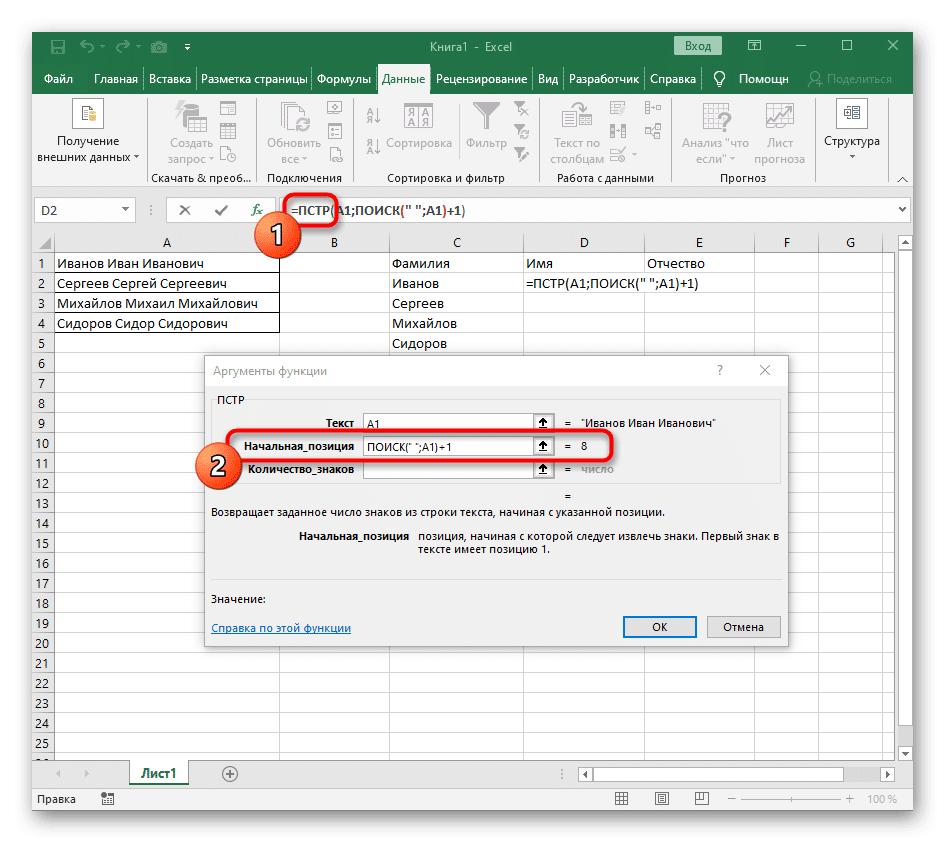
- Начальное положение строки необходимо определить по уже известной вспомогательной формуле ПОИСК().
- После того, как вы создали его и переместились, заполните его точно так же, как это было показано на предыдущем шаге. Используйте разделитель в качестве текста для поиска и укажите ячейку в качестве текста для поиска.
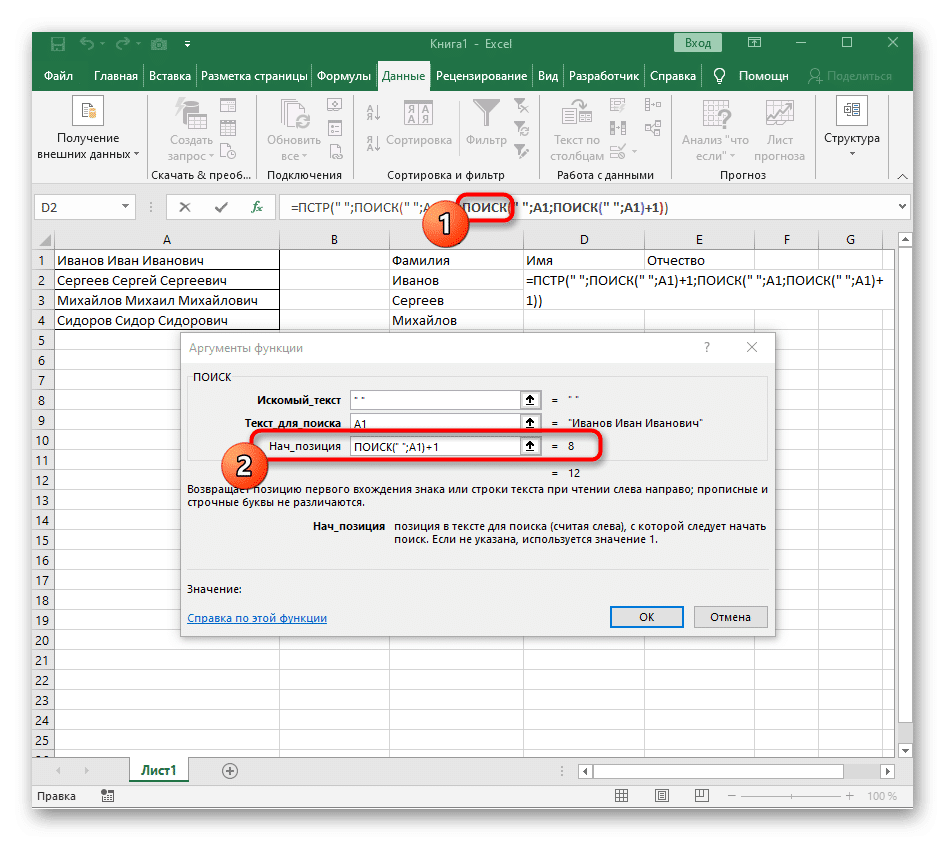
- Вернитесь к предыдущей формуле, где вы добавляете +1 к функции НАЙТИ в конце, чтобы начать отсчет со следующего символа после найденного пробела.
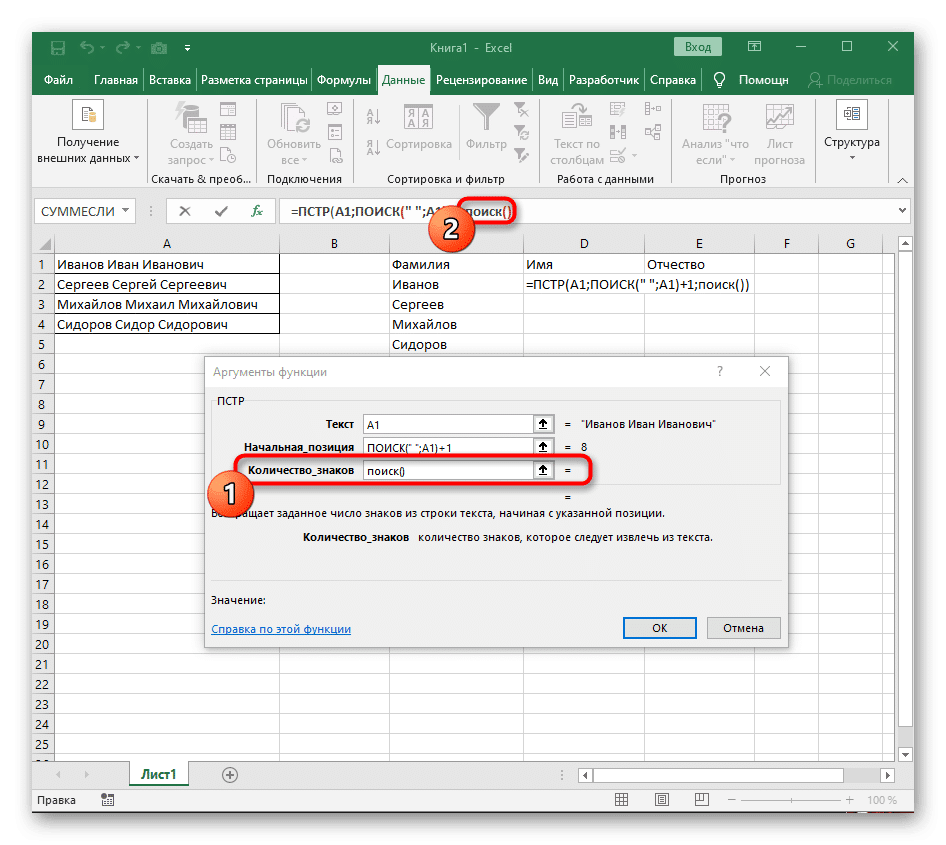
- Теперь формула уже может начать поиск строки с первого символа имени, но она еще не знает, где ее закончить, поэтому в поле «Number_of_chars» снова введите формулу SEARCH().
- Перейдите к его аргументам и заполните их как обычно.
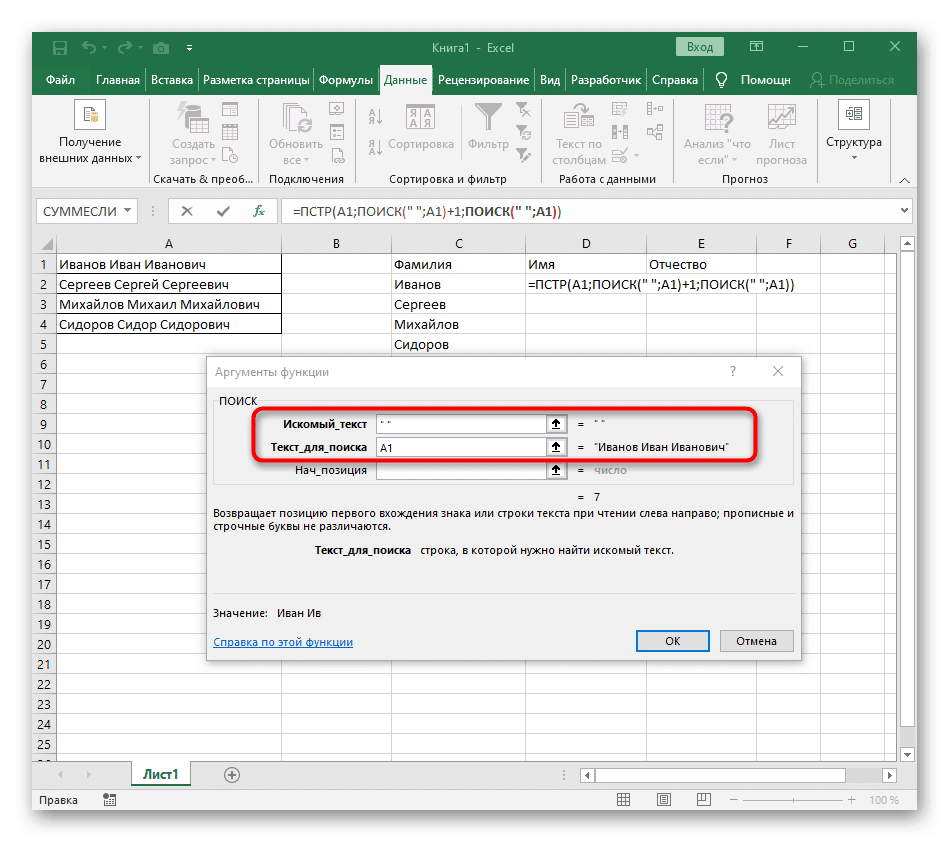
- Раньше мы не рассматривали начальную позицию этой функции, но теперь нам нужно вставить туда и SEARCH (), так как эта формула должна находить не первый пробел, а второй.
- Переходим к созданной функции и заполняем ее таким же образом.
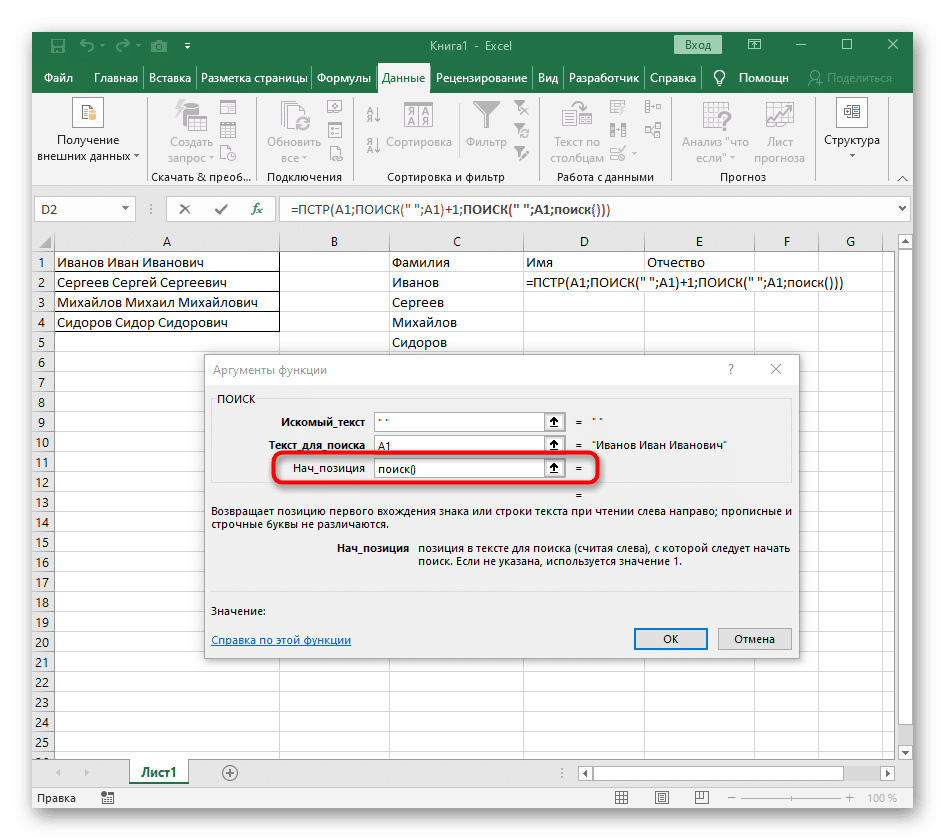
- Вернитесь к первому «ПОИСКУ» и добавьте +1 в конец «Start_position», потому что вам нужен не пробел для поиска строки, а следующий символ.
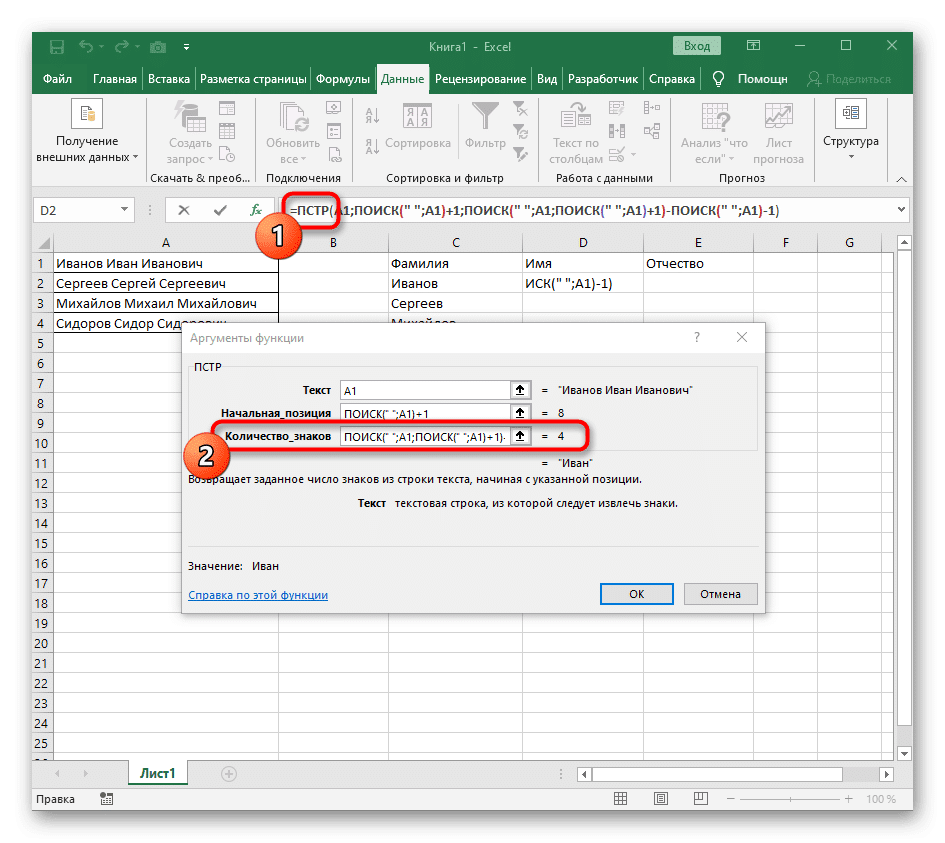
- Щелкните root = MID и поместите курсор в конец строки «Number_of_chars».
- Добавьте выражение -SEARCH («»; A1) -1), чтобы завершить вычисление пробелов.
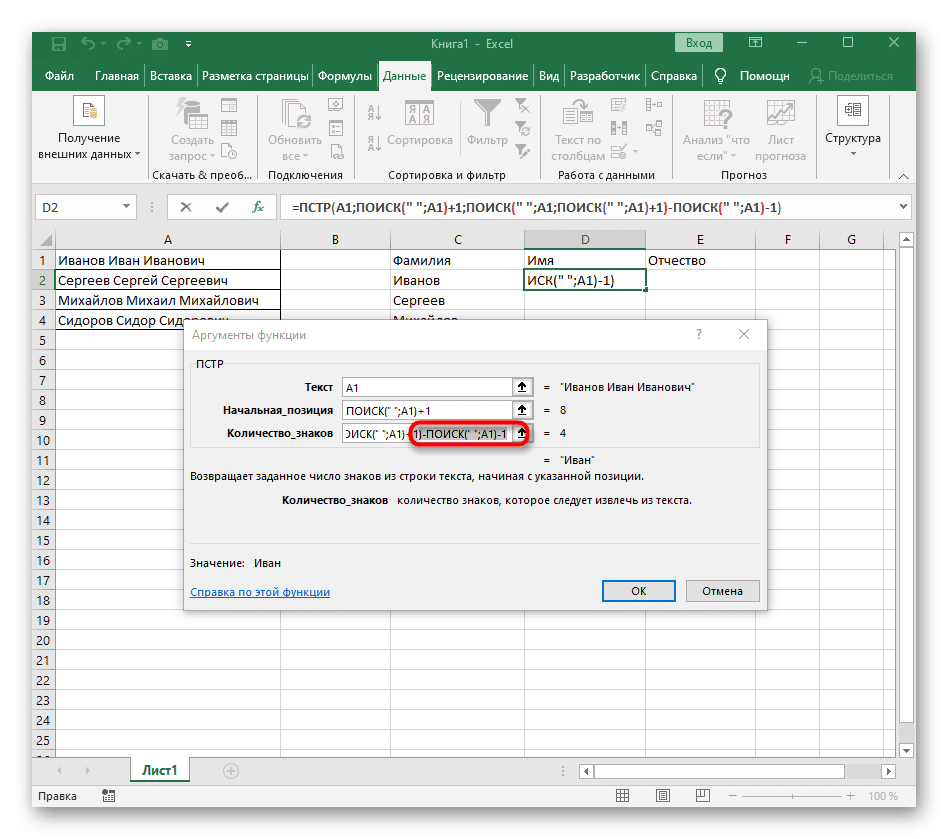
- Вернитесь к электронной таблице, растяните формулу и убедитесь, что слова отображаются правильно.
Формула оказалась отличной, и не все пользователи точно понимают, как она работает. Дело в том, что для поиска строки приходилось использовать одновременно несколько функций, определяющих начальную и конечную позиции пробелов, а затем из них вычитался символ, так что в результате эти самые пробелы не отображались. Следовательно, формула имеет следующий вид: = MID (A1; ПОИСК («»; A1) +1; ПОИСК («»; A1; ПОИСК («»; A1) +1) -ПОИСК («»; A1) — 1) Используйте это как пример, заменив номер ячейки текстом.
Шаг 3: Разделение третьего слова
Последний шаг нашей инструкции включает подразделение третьего слова, которое выглядит так же, как первое, но общая формула немного меняется.
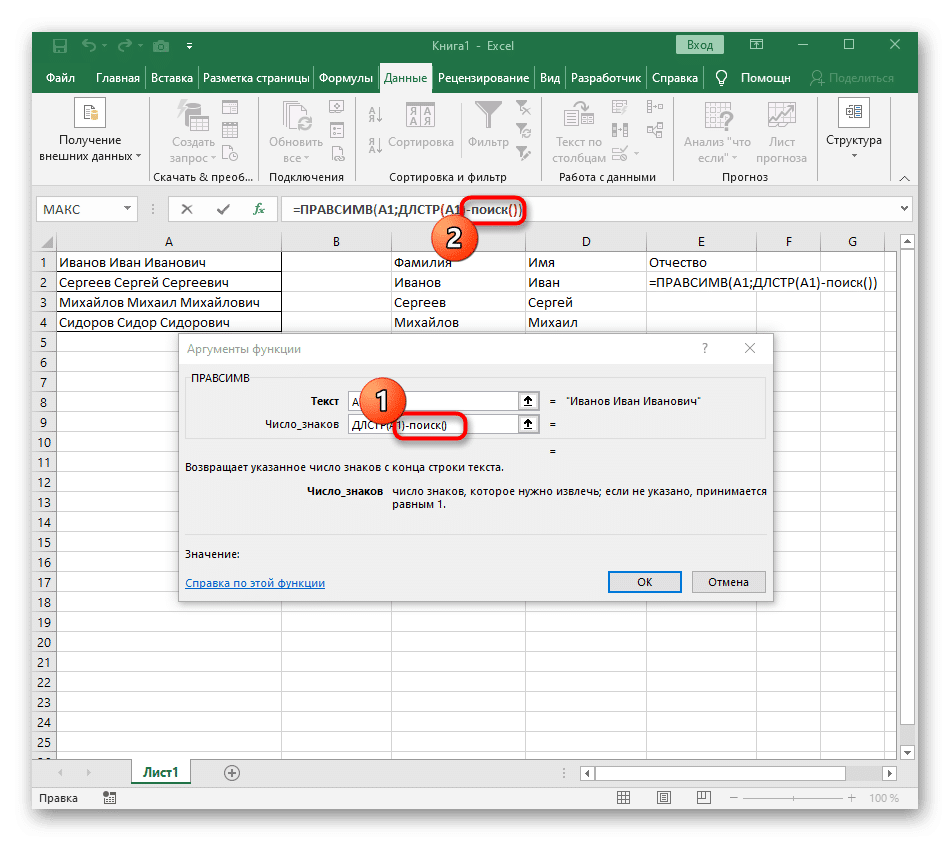
- В пустой ячейке для позиции будущего текста напишите = ПРАВО (и перейдите к аргументам этой функции.
- Используйте помеченную ячейку для разделения в виде текста.
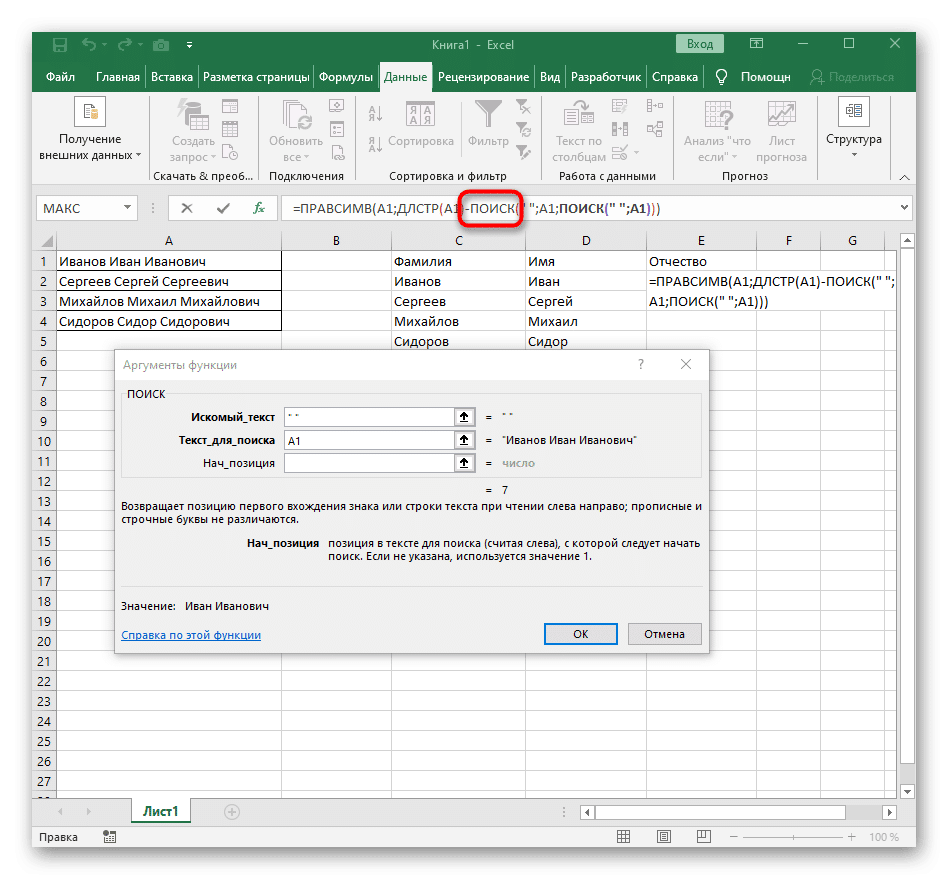
- На этот раз вспомогательная функция для поиска слова называется DLSTR (A1), где A1 — это та же ячейка, что и текст. Эта функция определяет количество символов в тексте, и нам останется только выбрать подходящие.
- Для этого добавьте -SEARCH () и отредактируйте эту формулу.
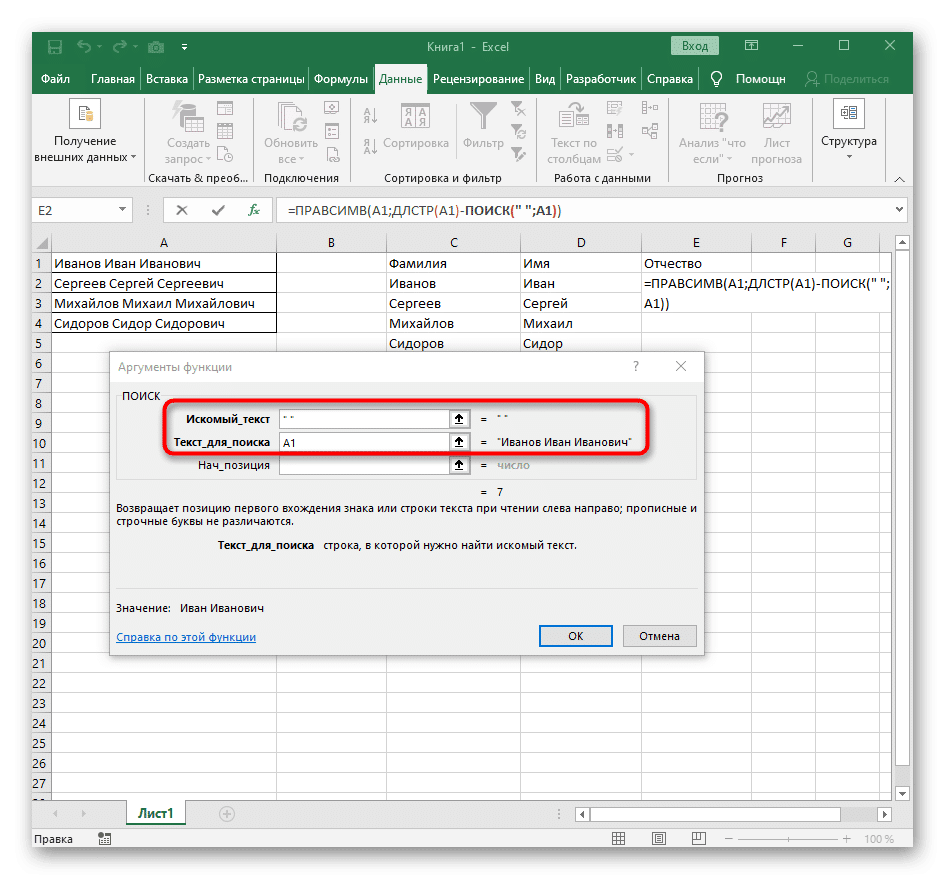
- Войдите в уже знакомую структуру, чтобы найти первый разделитель в строке.
- Добавьте еще один ПОИСК () для начальной позиции().
- Придайте ему такую же структуру.
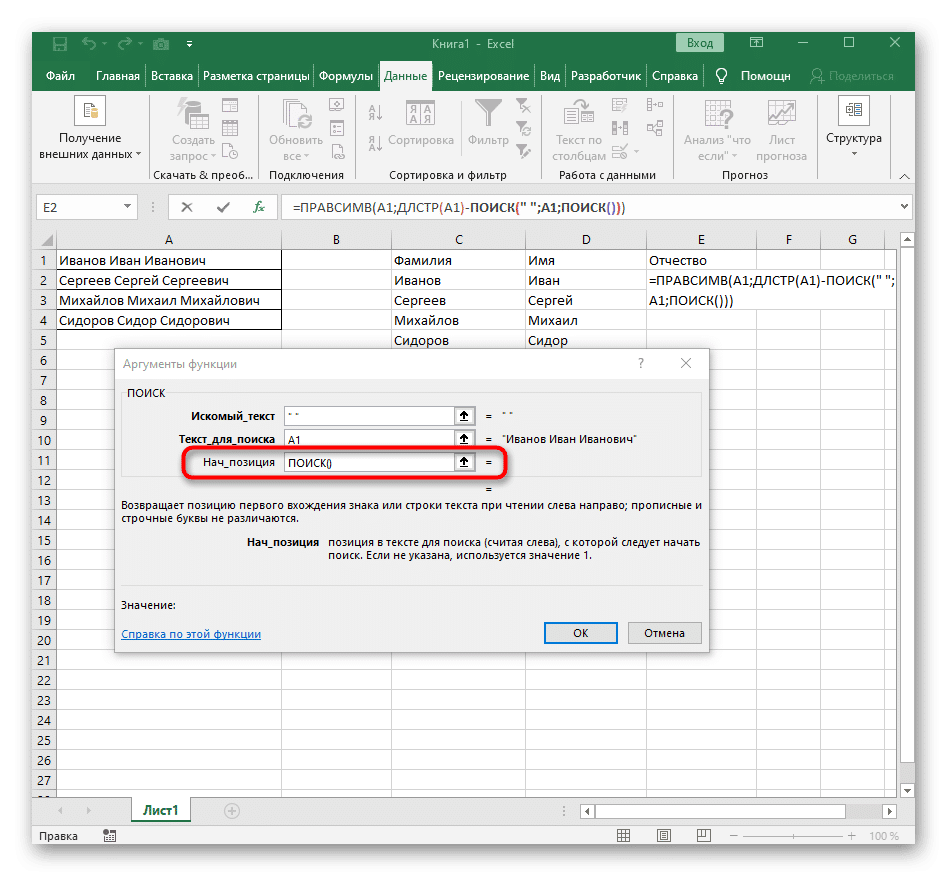
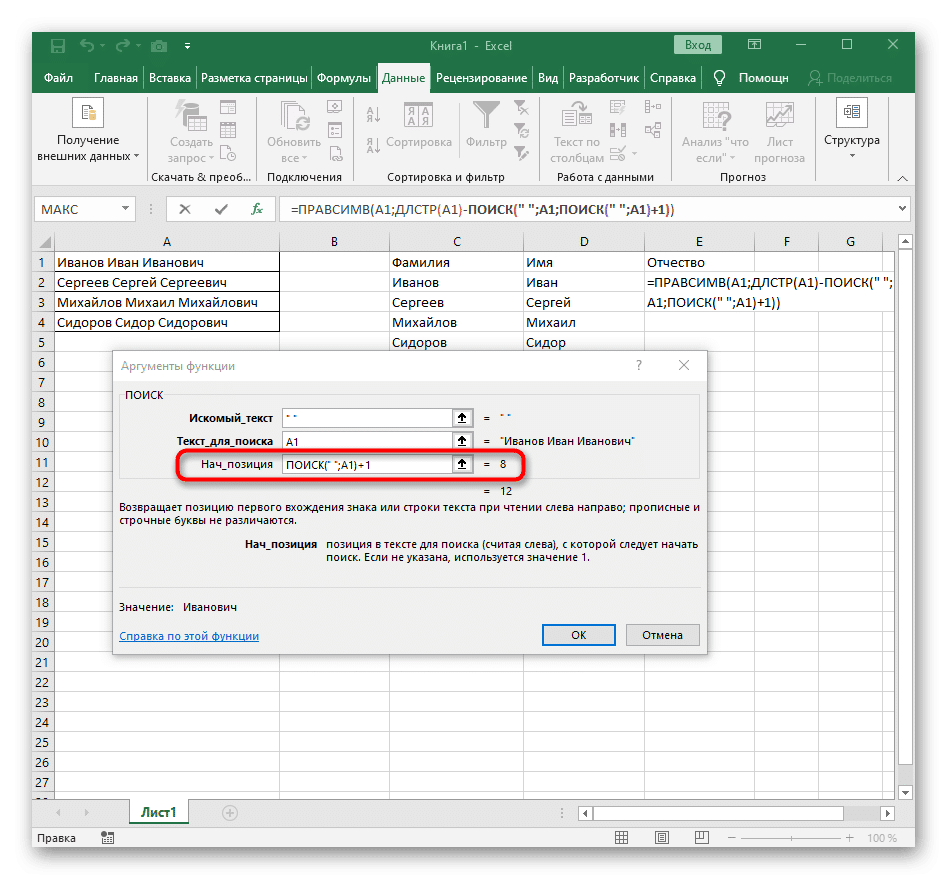
- Вернуться к предыдущей формуле ПОИСКА».
- Добавьте +1 для его начальной позиции.
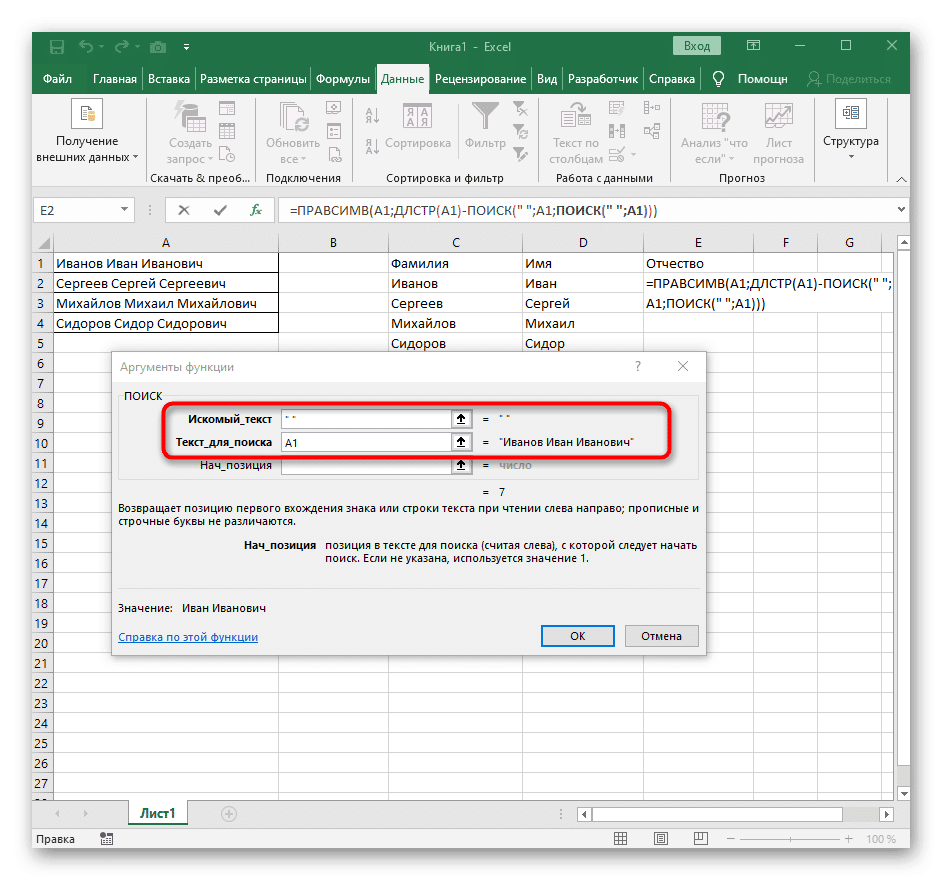
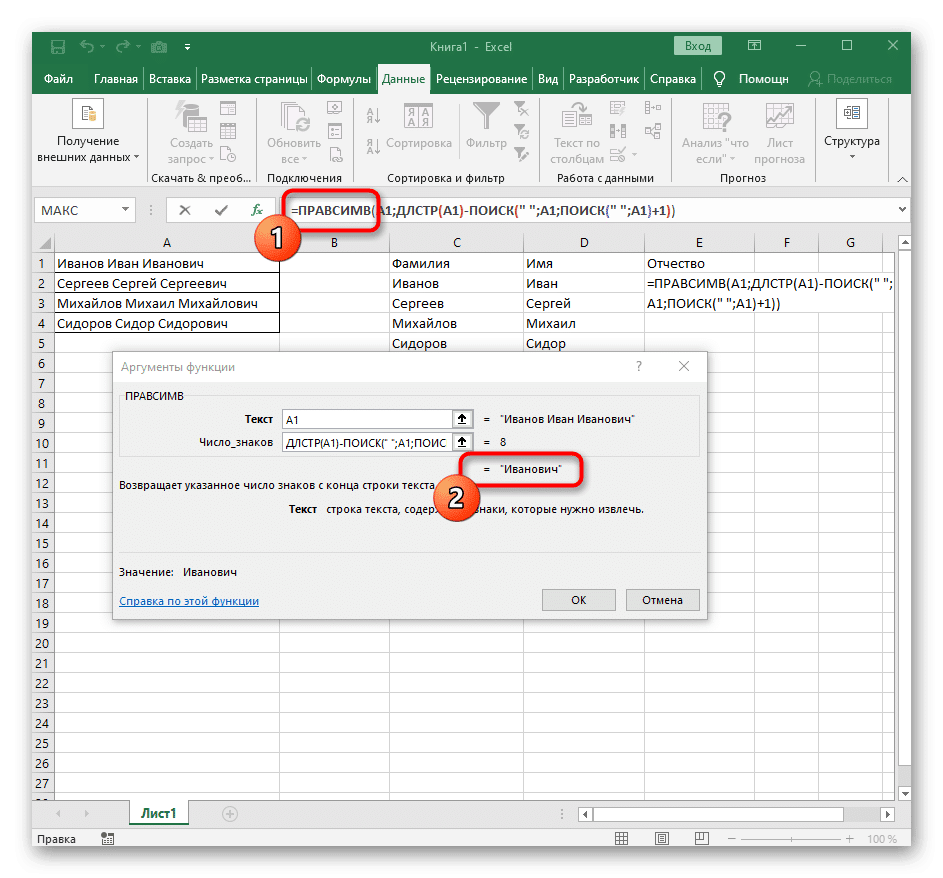
- Перейдите к корню ПРАВИЛЬНОЙ формулы и убедитесь, что результат отображается правильно, прежде чем подтверждать изменения. Полная формула в этом случае: = RIGHT (A1; DLSTR (A1) -SEARCH («»; A1; SEARCH («»; A1) +1)).
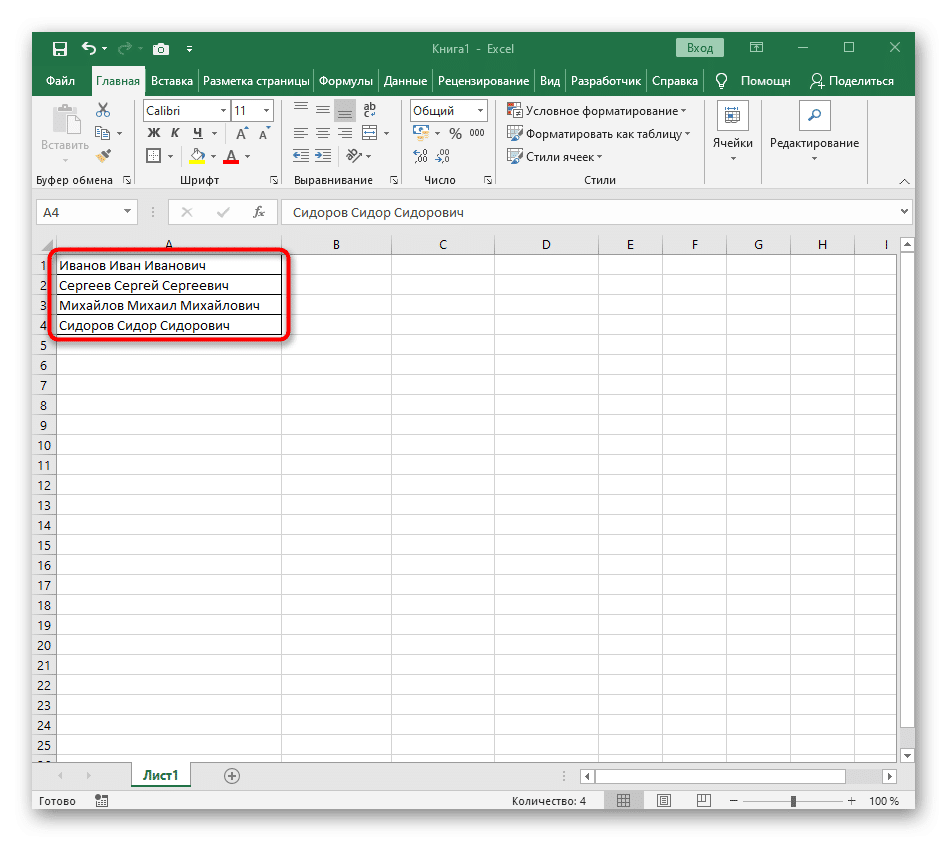
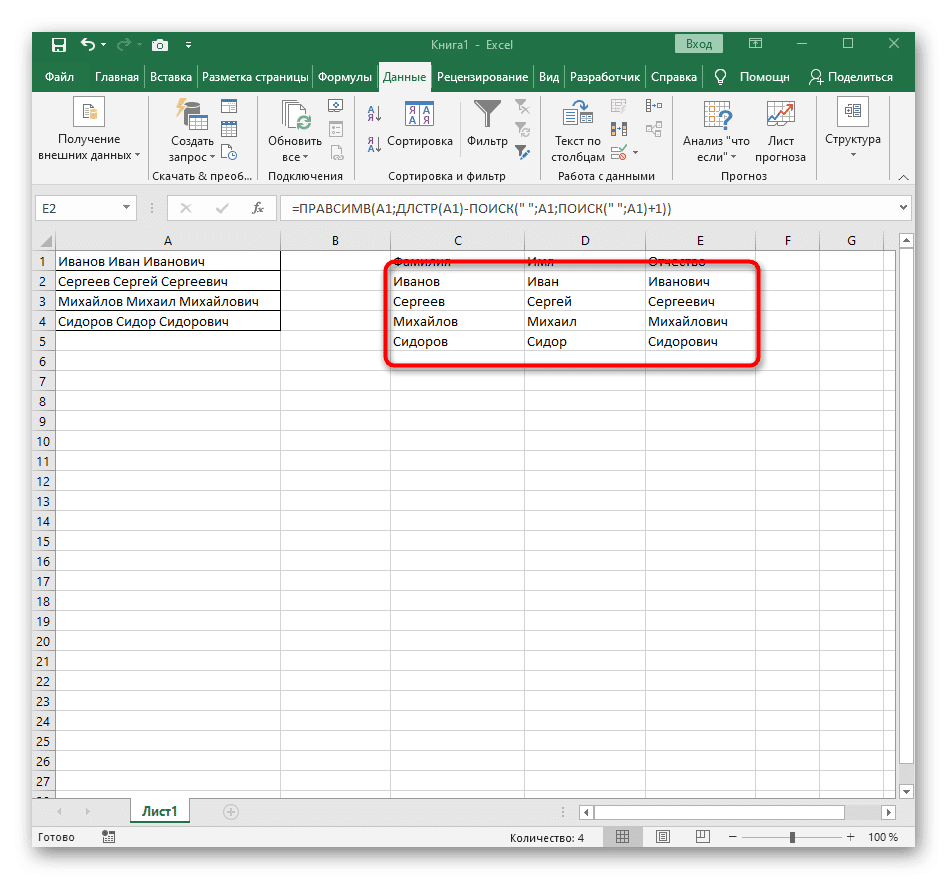
- В результате на следующем экране вы можете увидеть, что все три слова разделены правильно и находятся в своих столбцах. Для этого мне пришлось использовать множество вспомогательных формул и функций, но это позволяет динамически расширять таблицу и не беспокоиться о том, что придется каждый раз снова разбивать текст. При необходимости просто разверните формулу, переместив ее вниз, чтобы автоматически повлиять на последующие ячейки.